作为智能对话系统,ChatGPT最近两天爆火,引起了广泛关注。相较于以前,人工智能技术已经有了很大进步。在过去的两年半中,GPT-3在NLP领域的发布引起了轰动,而多模态领域则是以DaLL E2、Stable Diffusion为代表的Diffusion Model。而现在,ChatGPT的出现也引起了极大的反响,这也是AIGC范畴中的一个重要应用。
那么,ChatGPT到底采用了怎样的技术才能做到如此卓越的效果?它能否取代Google、百度等现有的搜索引擎?如果能,是为什么?如果不能,又是为什么?
从技术角度来看,ChatGPT是一个基于自然语言处理技术的智能对话系统。它使用了大规模的语言模型来生成自然对话,从而实现了比较高水平的语言理解和语言生成能力。相较于传统的搜索引擎,ChatGPT更注重语义理解和上下文关联,它能够更好地理解用户的意图和情境,并提供更加个性化的回答。
虽然ChatGPT在智能对话领域已经取得了很大的成功,但它并不能完全取代现有的搜索引擎。毕竟,搜索引擎还具有非常重要的功能,比如大规模信息检索、搜索结果排序和广告投放等。ChatGPT的优势在于对话交互,而搜索引擎的优势则在于信息检索和广告投放等方面。因此,ChatGPT和搜索引擎是两种不同的技术,各有优缺点,不能简单地互相替代。
ChatGPT的技术原理
ChatGPT是一个智能对话系统,它基于GPT 3.5大规模语言模型(LLM)的基础上,采用“人工标注数据+强化学习”(RLHF)的方法进行Fine-tune预训练语言模型。这个过程的主要目的是让模型能够更好地理解人类的命令和指令的含义,例如生成小作文、知识回答、头脑风暴等不同类型的问题。同时,这个过程也让模型学会了如何判断一个回答是否是优质的,例如是否包含丰富的信息、对用户有帮助、不包含歧视信息等多种标准。
这个技术路线的设计非常巧妙,因为它充分利用了人类的智慧和机器的学习能力。通过人工标注数据,我们可以让模型更快地学习到人类的知识和经验;通过强化学习,我们可以让模型不断地优化自身的表现,从而获得更好的效果。这种技术路线也是当前智能对话系统的主流方法之一,它已经被广泛应用于各种领域,包括客服、教育、医疗等。
在“人工标注数据+强化学习”框架下,具体而言,ChatGPT的训练过程分为以下三个阶段:
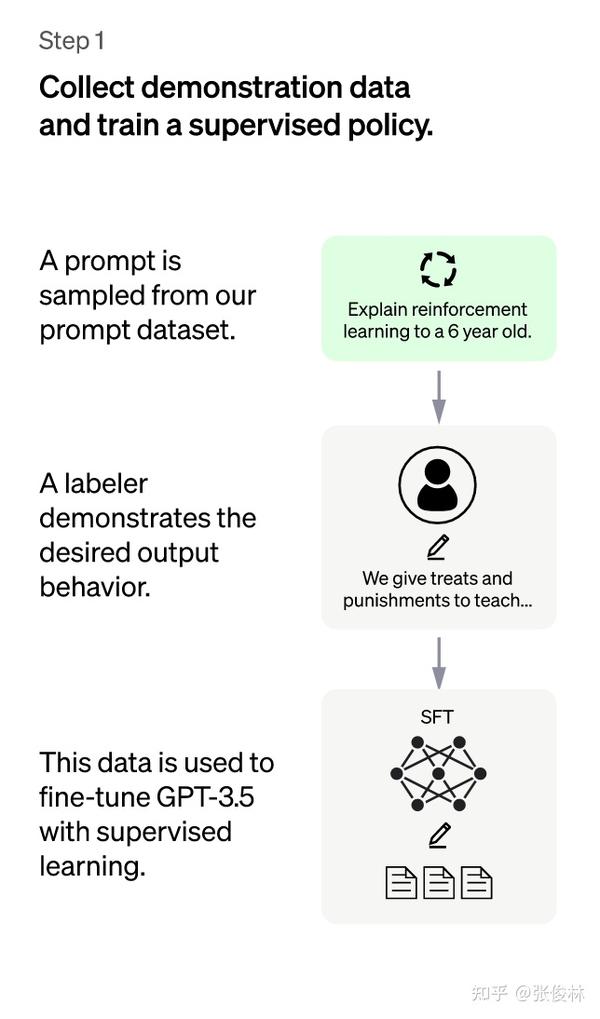
ChatGPT是一个智能对话系统,它通过多个阶段的训练来不断提高自身的理解和生成能力。在第一阶段中,我们采用了监督策略模型,旨在让GPT 3.5模型能够初步理解人类不同类型指令中蕴含的不同意图,并生成高质量的回答。
具体来说,我们从测试用户提交的prompt中随机抽取一批数据,然后通过专业的标注人员给出指定prompt的高质量答案。接着,我们使用这些人工标注好的<prompt,answer>数据来Fine-tune GPT 3.5模型,从而让它具备理解人类prompt中所包含意图并给出相对高质量回答的能力。
尽管这个过程已经让GPT 3.5初步具备了一定的能力,但是它仍然存在一些挑战和限制。比如,它可能仍然无法理解一些复杂的指令和问题,或者生成的回答可能并不是最优的。因此,在后续的训练中,我们还需要采用更加先进和复杂的技术来进一步提高模型的表现。
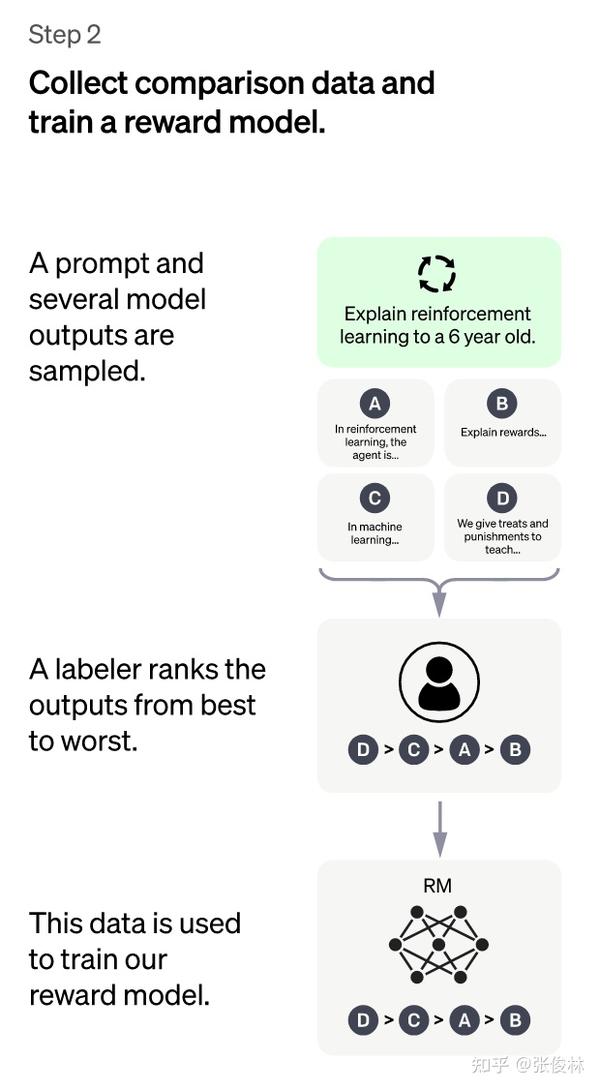
第二阶段是ChatGPT训练的另一个重要阶段,其主要目的是训练回报模型(Reward Model, RM)。这个阶段的训练数据是由第一阶段Fine-tune好的冷启动模型生成的K个不同的答案,接着我们再对这些答案进行人工标注和排序,以此作为训练数据来训练RM模型。
具体来说,我们会随机抽样一批用户提交的prompt,并使用冷启动模型为每个prompt生成K个不同的答案。接下来,我们会邀请专业的标注人员对这K个答案进行排序,考虑到诸多标准,例如答案的相关性、信息丰富度、是否包含有害信息等。这样,我们就得到了一组有序的<prompt,answer1>,<prompt,answer2>….<prompt,answerK>数据,这就是此阶段人工标注的数据。
接着,我们准备利用这个排序结果数据来训练RM模型,采用的训练模式是pair-wise learning to rank。对于K个排序结果,我们会通过两两组合来形成不同的训练数据对,ChatGPT会采用pair-wise loss来训练RM模型。RM模型接受一个输入<prompt,answer>,并给出评价回答质量的回报分数Score。对于一对训练数据<answer1,answer2>,我们假设人工排序中answer1排在answer2前面,那么Loss函数则会鼓励RM模型对<prompt,answer1>的打分要比<prompt,answer2>的打分要高。
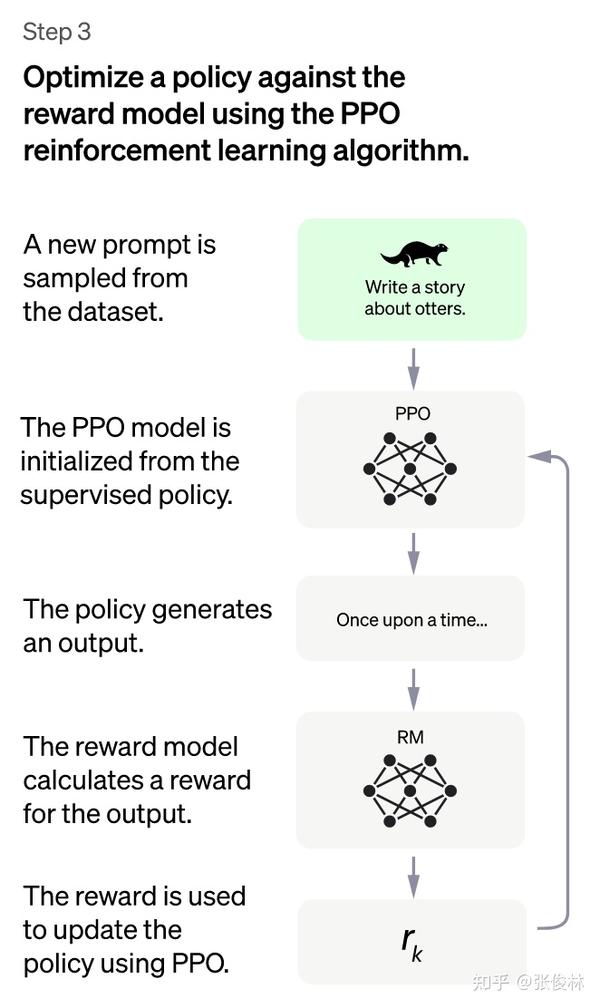
第三阶段是ChatGPT模型训练的最后一个阶段,采用的是强化学习来增强预训练模型的能力。与前两个阶段不同的是,这一阶段不需要人工标注数据,而是利用上一阶段学习好的RM模型,以RM打分结果来更新预训练模型参数。具体来说,我们会从用户提交的prompt里随机抽样一批新的命令,这些命令与前两个阶段所用的不同,这对于提升LLM模型理解指令的泛化能力非常有帮助。然后,我们使用冷启动模型来初始化PPO模型的参数,并使用PPO模型为随机抽取的prompt生成回答answer。接着,我们利用上一阶段训练好的RM模型,给answer打分并计算score,这个score就是RM赋予整个回答(由单词序列构成)的reward。有了单词序列的最终reward,我们就可以把每个单词看作一个时间步,把reward由后往前依次传递,由此产生的策略梯度可以更新PPO模型参数。这是标准的强化学习过程,目的是训练LLM产生高reward的答案,也即是产生符合RM标准的高质量回答。
如果我们不断重复第二和第三阶段,LLM模型的能力会越来越强。因为第二阶段通过人工标注数据来增强RM模型的能力,而第三阶段,经过增强的RM模型对新prompt产生的回答打分会更准,并利用强化学习来鼓励LLM模型学习新的高质量内容,这起到了类似利用伪标签扩充高质量训练数据的作用,于是LLM模型进一步得到增强。可以说,第二阶段和第三阶段相互促进,这是为何不断迭代会有持续增强效果的原因。
不过,我认为第三阶段采用强化学习策略并不一定是ChatGPT模型效果特别好的主要原因。如果我们不采用强化学习,而是采用类似第二阶段的做法,对于一个新的prompt,冷启动模型可以产生k个回答,由RM模型分别打分,然后选择得分最高的回答,构成新的训练数据<prompt,answer>,再用这些数据去fine-tune LLM模型,效果也未必会比强化学习差很多。因为在第三阶段,无论采取哪种技术模式,本质上都是利用第二阶段学会的RM,起到扩充LLM模型高质量训练数据的作用。
以上就是ChatGPT模型的训练流程,这个模型基本遵循instructGPT的结构和训练流程,只是在收集标注数据方法上有些区别。可以预见的是,这种Reinforcement Learning from Human Feedback技术会快速应用到其它内容生成方向,比如图片、音频、视频等其它模态的生成领域。值得关注的是,DeepMind的sparrow也采用了类似技术,虽然与instructGPT的训练流程有些不同,我认为以下这些内容可能会更好地解释ChatGPT模型的训练流程。
chatGPT能否取代Google、百度等传统搜索引擎
既然看上去chatGPT几乎无所不能地回答各种类型的prompt,那么一个很自然的问题就是:ChatGPT或者未来即将面世的GPT4,能否取代Google、百度这些传统搜索引擎呢?我个人觉得目前应该还不行,但是如果从技术角度稍微改造一下,理论上是可以取代传统搜索引擎的。

当下的ChatGPT还无法替代搜索引擎,这是为什么呢?原因主要有三:首先,对于某些类型的问题,ChatGPT可能会提供看似有道理,实则错误的答案(比如@Gordon Lee的例子),这会让用户感到困惑:究竟该信任ChatGPT还是不信任呢?其次,ChatGPT当前的模型基于GPT大模型加上标注数据的训练,对于新知识不太友好。新知识不断涌现,重新预训练GPT模型的成本过高,使用Fine-tune模式又会导致原有知识的遗忘。如何实时融入新知识是一个巨大的挑战。最后,ChatGPT的训练成本和在线推理成本都很高,如果面向亿万用户的实际搜索需求,OpenAI无法承担,但如果收费,用户基数会大幅减少。以上三个问题导致ChatGPT目前还不能替代传统搜索引擎。
那么这些问题能否得到解决呢?实际上,如果我们以ChatGPT技术路线为主体框架,并吸收其他对话系统采用的技术手段来改进ChatGPT,那么除了成本问题外的前两个技术问题,从技术角度看都是可以得到很好解决的。我们只需要在ChatGPT的基础上,引入sparrow系统以下能力:基于检索结果的生成证据展示,以及采用LaMDA系统的检索模式来引入新知识,这样就能够实现新知识的及时引入和生成内容的可信度验证。
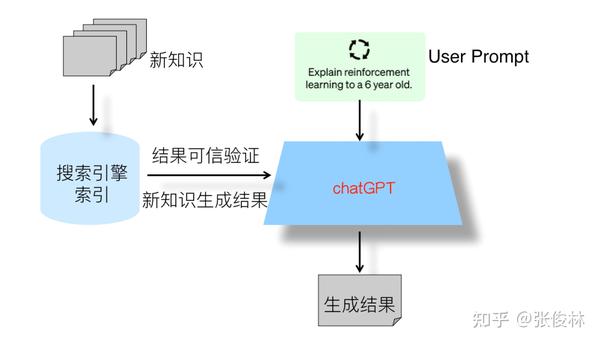
在考虑下一代搜索引擎的设计时,我认为采用双引擎结构是比较可行的。具体来说,这个双引擎结构由传统搜索引擎和ChatGPT组成,其中ChatGPT是主引擎,传统搜索引擎则是辅助引擎。传统搜索引擎的两个主要辅助功能是:首先,对于ChatGPT回答的知识类问题,传统搜索引擎可以提供相关内容片段和链接,以验证答案的可信性,从而解决用户不确定性的问题。然而,并不是所有类型的问题都需要进行可信性验证,对于完全自由生成类型的问题,如让ChatGPT写一篇关于某个主题的小作文,这种问题则无需进行可信性验证。其次,传统搜索引擎可以用于及时补充新知识。由于新知识的涌现速度难以追赶,因此我们可以将新知识存储在搜索引擎的索引中。当ChatGPT无法回答具有时效性的问题时,它可以转向传统搜索引擎来提取相应的答案,或根据搜索引擎返回的相关片段和用户输入的问题来生成答案。这种技术手段的具体实现可以参考LaMDA。
除了以上技术手段,我认为引入综合的Reward Model可以对ChatGPT进行进一步的模型改进。具体来说,可以参考sparrow系统的方法,将答案的信息量和合理性等方面的标准采用一个RM,而将有害信息等方面的标准单独采用一个RM,这样可以更加清晰和有效地进行判断和标注。然而,由于不同类型标准的冲突,将多个标准融合到一个Reward Model中可能会导致判断过于复杂和低效。因此,我认为这种模式应该被引入到ChatGPT中,以进一步优化模型。
通过吸取各种现有技术的优点,我相信可以解决ChatGPT目前所面临的问题。虽然模型训练成本和推理成本仍然是一个关键技术瓶颈,但从产生内容的质量和效果上来看,ChatGPT可以取代现有搜索引擎。未来的搜索引擎可能会以用户智能助手APP的形式存在,但在过渡阶段中,传统搜索引擎可能仍然是主引擎,ChatGPT则是辅助引擎。这种过渡期可能会持续很长一段时间,直到大模型训练成本大幅下降才可能进行全面的转换。在这个过渡期中,大多数用户对于搜索引擎的需求可能可以通过ChatGPT的Top 1结果得到满足,而对于少数无法满足的需求,用户可以采用现有搜索引擎的翻页搜索模式。

